Veja o código
entidade nota_teste
1 Distrito A 650
2 Distrito B 620
3 Distrito C 680
4 Distrito D 590
5 Distrito E 710IBM0288 - 2026.1
Modelo:
\[ \text{TestScore}_i = \beta_0 + \beta_1 \ \text{STR}_i + u_i \]
Média condicional:
\[ E(\text{TestScore} \mid \text{STR}) = \beta_0 + \beta_1\,\text{STR} \]
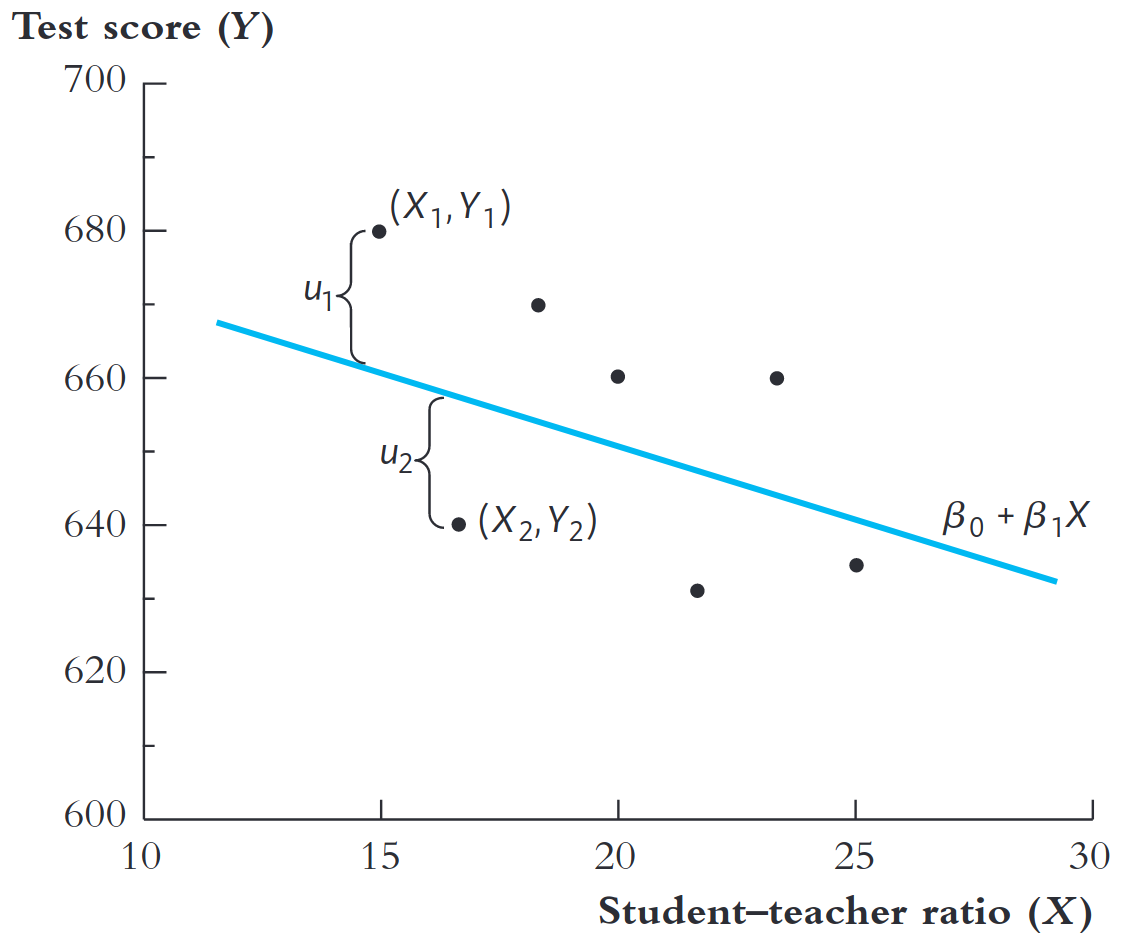
Podemos estimar \(\beta_0\) e \(\beta_1\) a partir de uma amostra.
Escolher \(\beta_0\),\(\beta_1\) para ajustar melhor aos dados.

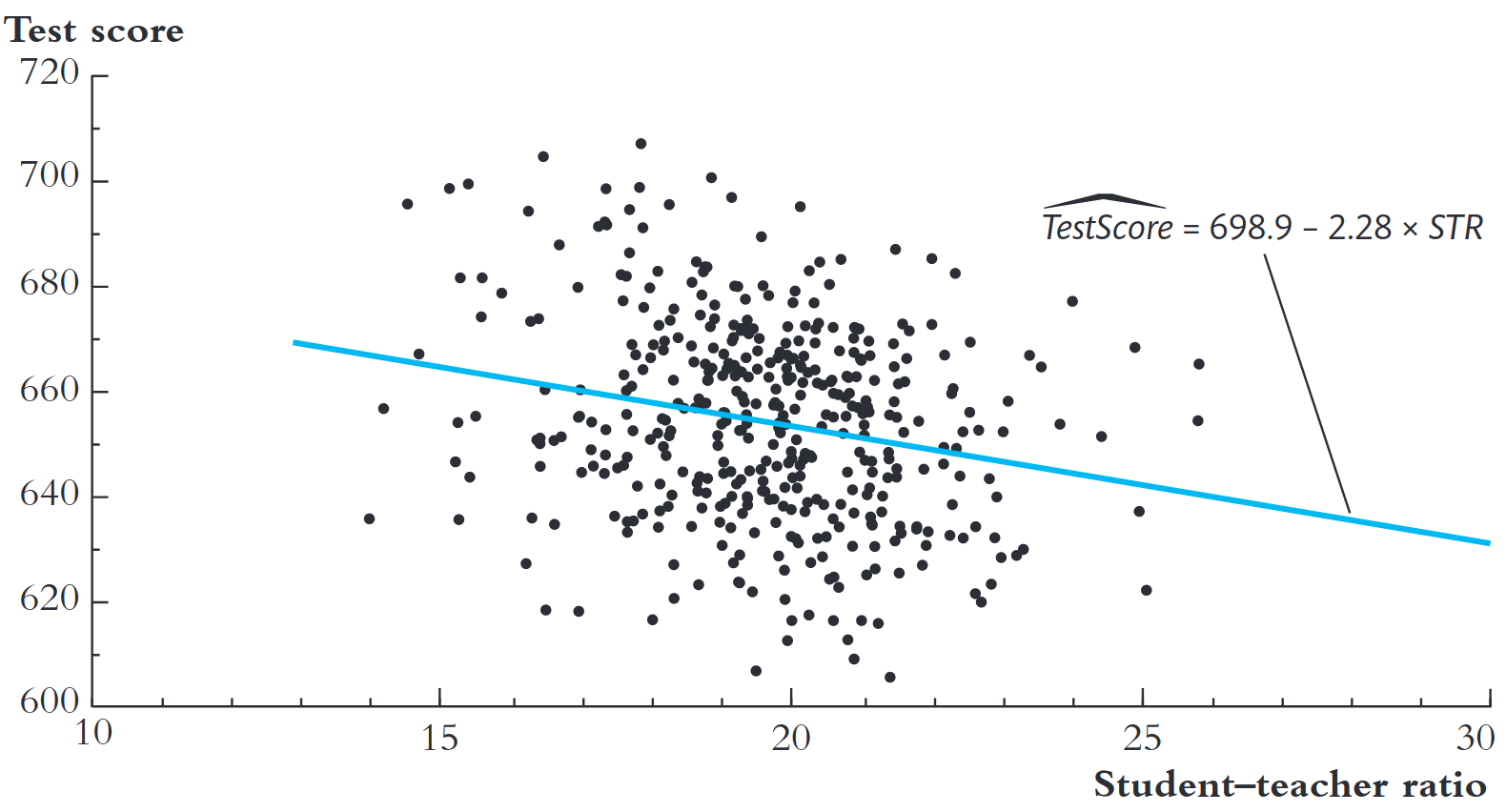
Importante
Não iremos focar nas medidas de ajuste neste curso. Essas medidas têm deixado de ser enfatizadas. O foco é nas hipóteses de identificação de causalidade!
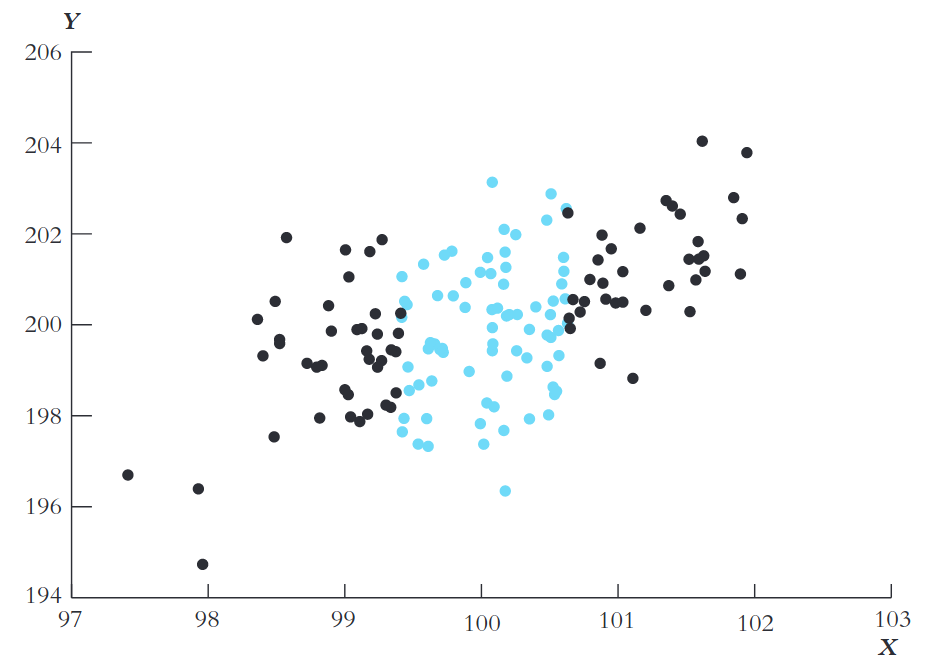
O número de observações em preto e azul são iguais
Todas observações vêm da mesma distribuição conjunta
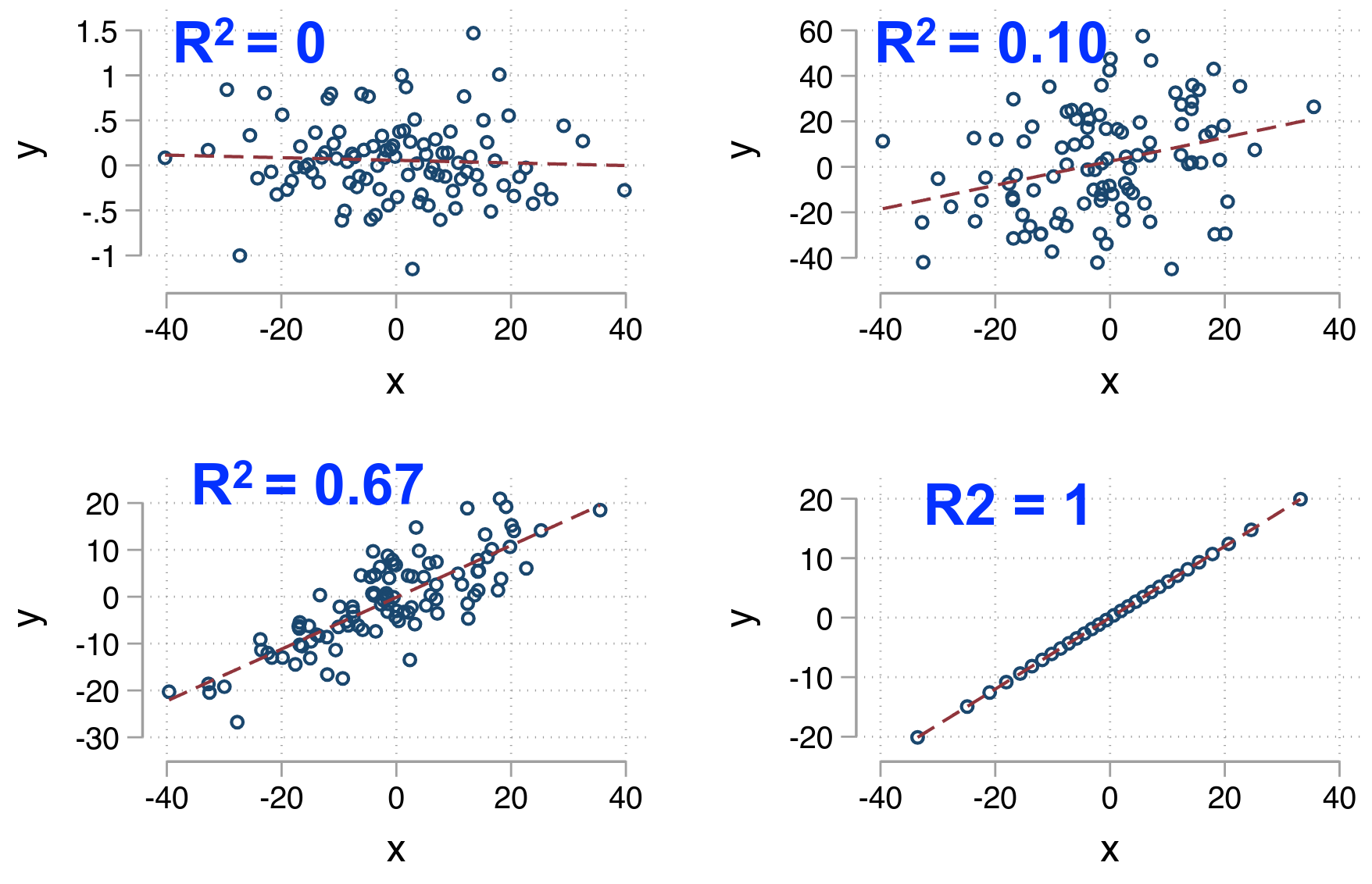
Para qual dos dois grupos a reta de regressão é melhor estimada?
Aumentar dispersão de X diminui a \(var(\beta_1)\)
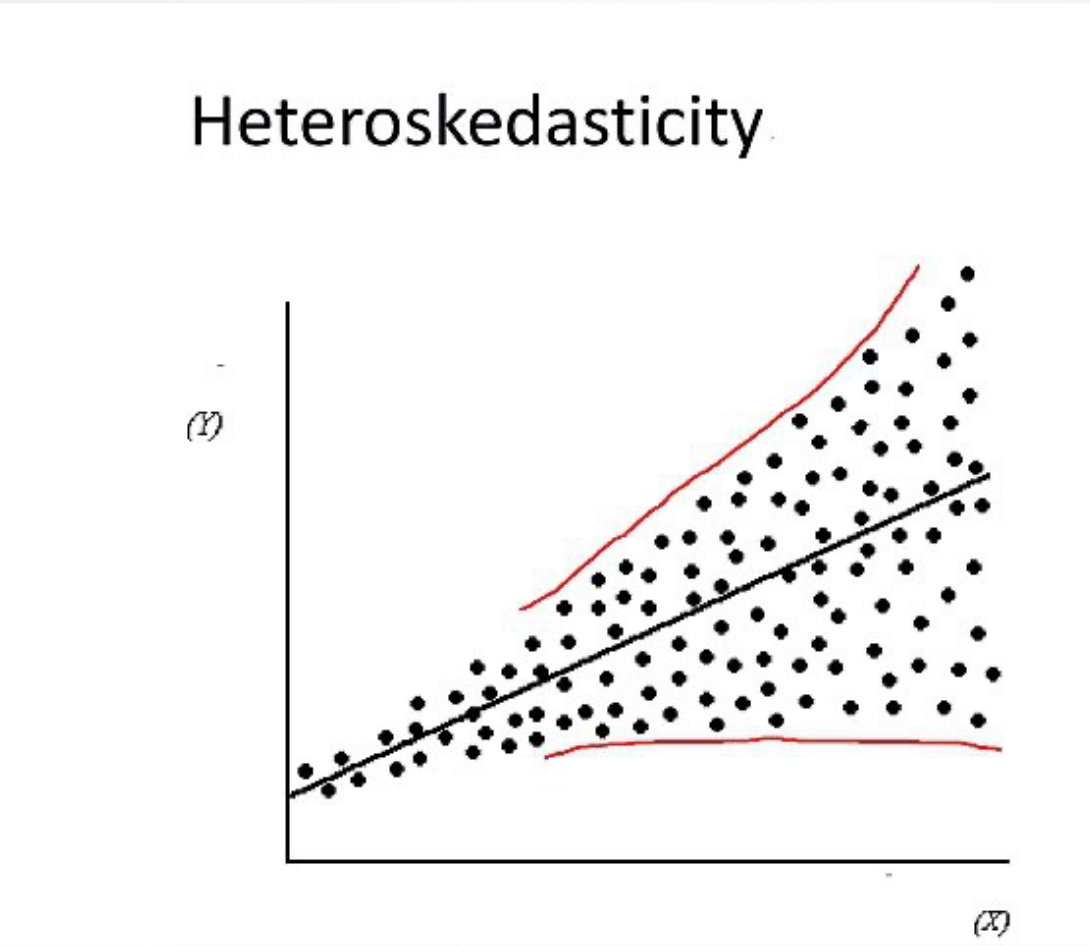
Quando devemos usar desvios-padrões sob homocedasticidade ou não robustos?
Dica
NUNCA! Os devios-padrão robustos são sempre mais adequados já que também são válidos sob a hipótese de homocedasticidade.
\[ H_0:\; \beta_k=\beta_{k,0} \qquad\text{vs.}\qquad H_1:\; \beta_k\neq\beta_{k,0} \]
Passos práticos para testar \(H_0\):
Estime \(\hat\beta_1\) e \(SE(\hat\beta_1)\).
Calcule a estatística \(t\)
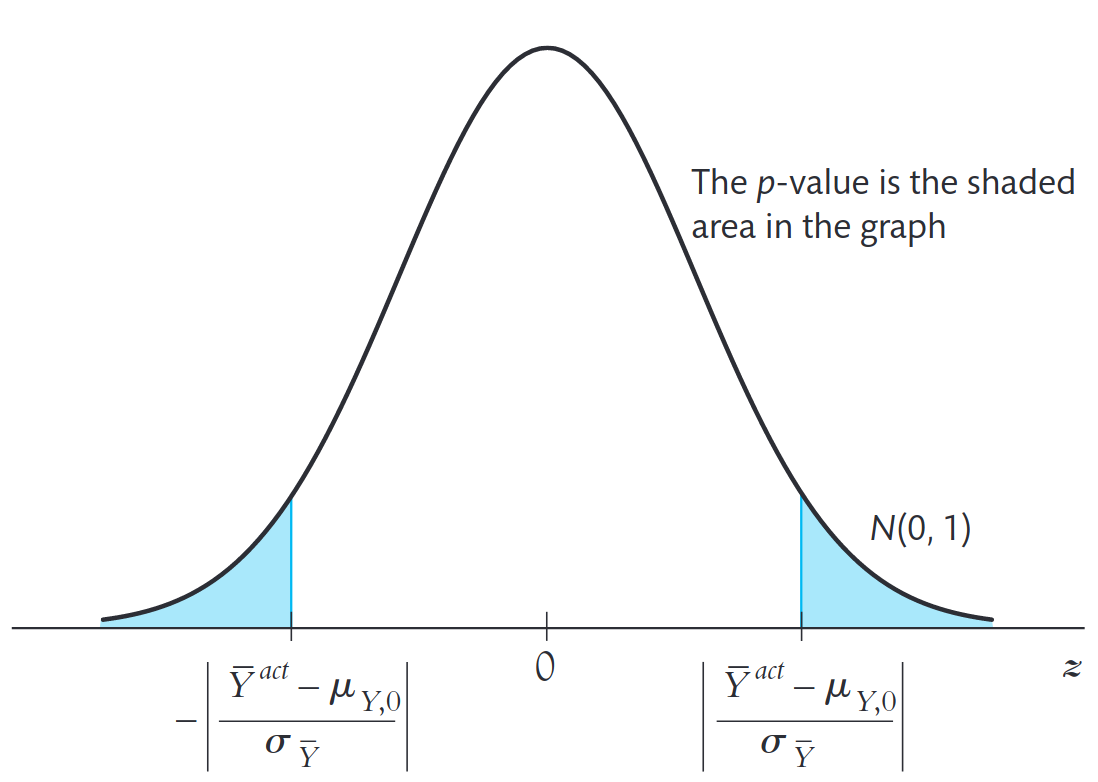
Calcule o p-valor
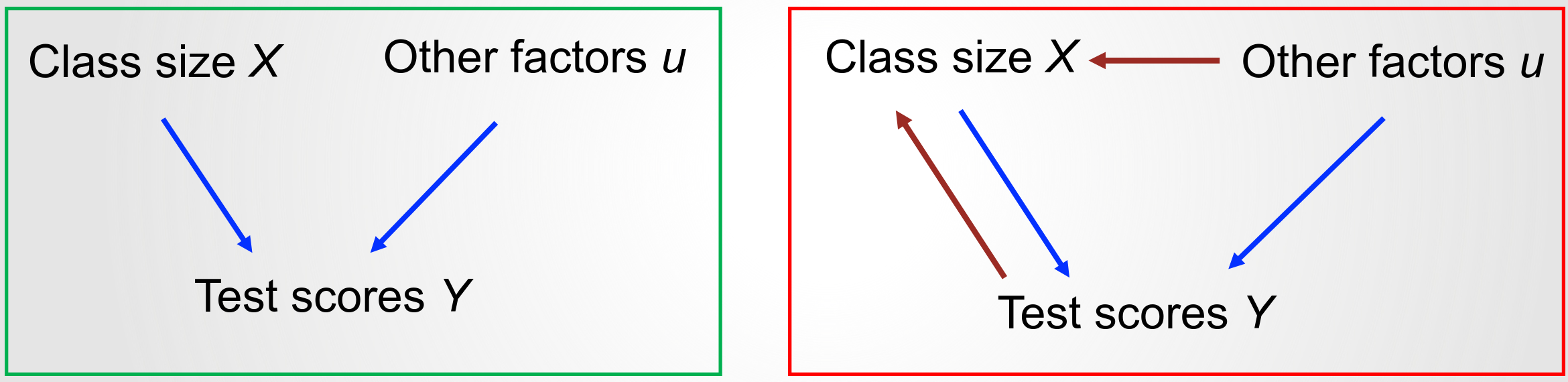
Efeito causal do tamanho da sala?
Ou alguma outra coisa?
Quando uma das setas vermelhas está presentes, não é possível garantir que os coeficientes de MQO capturam o efeito causal.
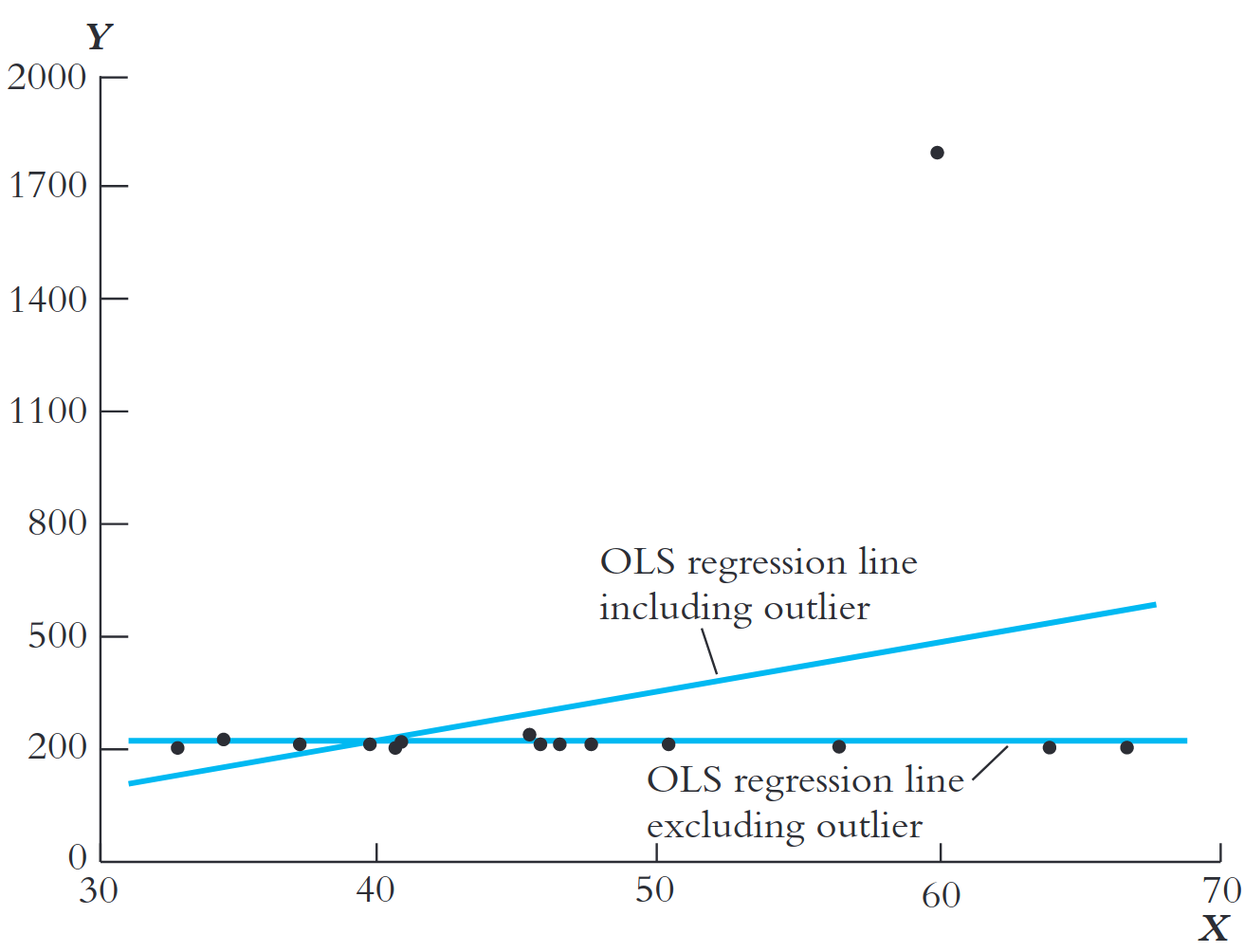
Pontos extremos em \(X\) ou \(Y\) podem distorcer a reta.