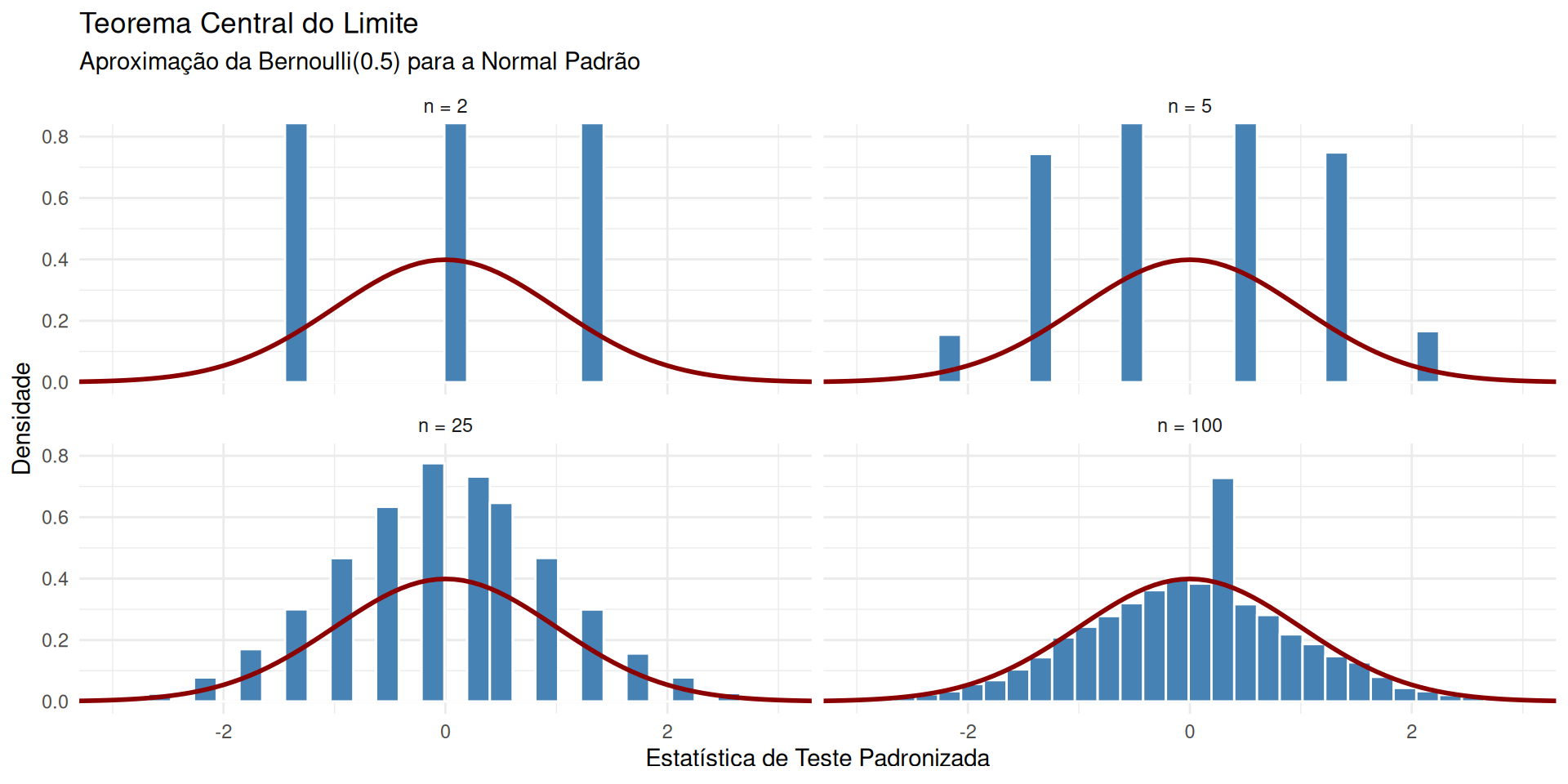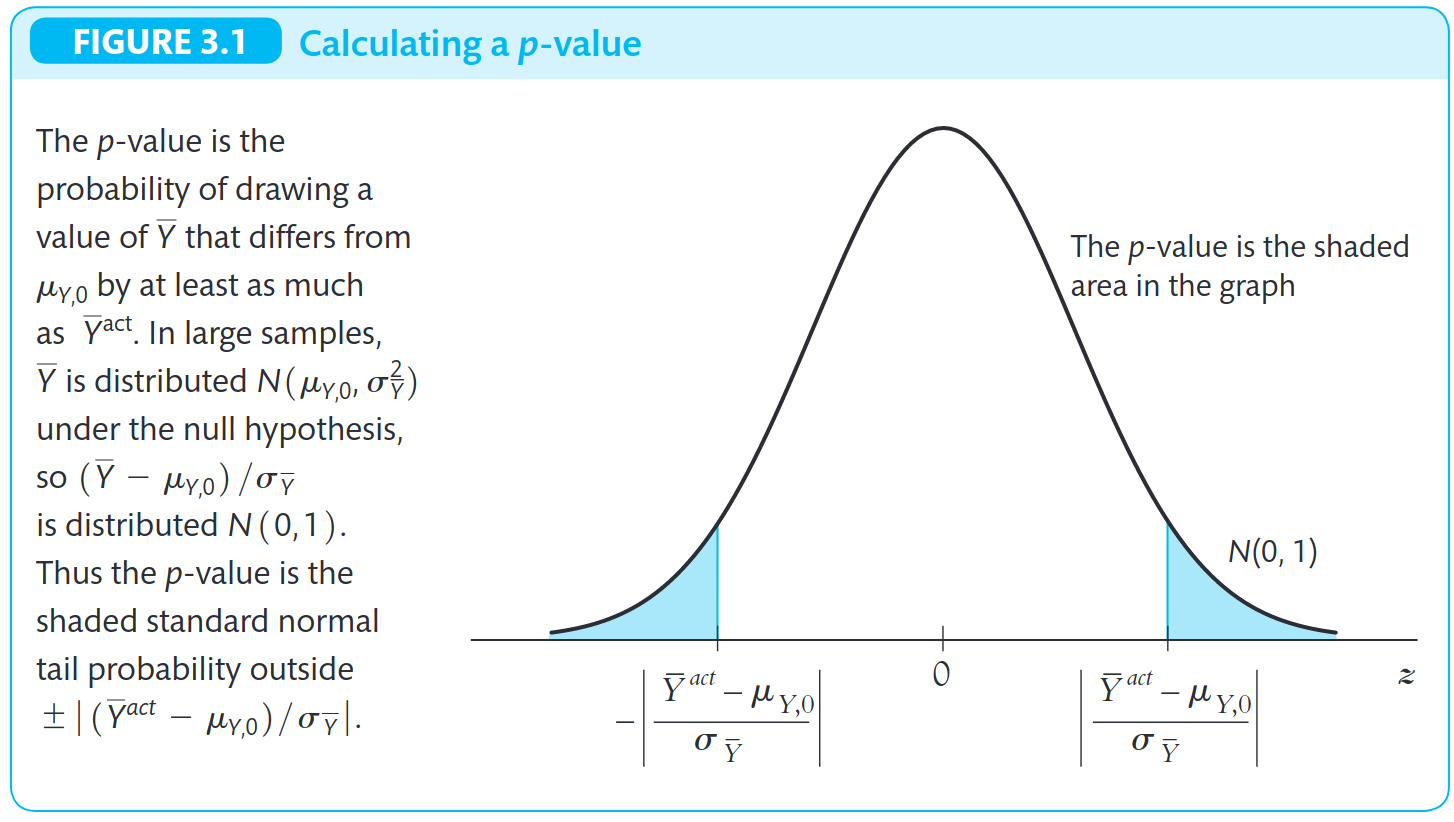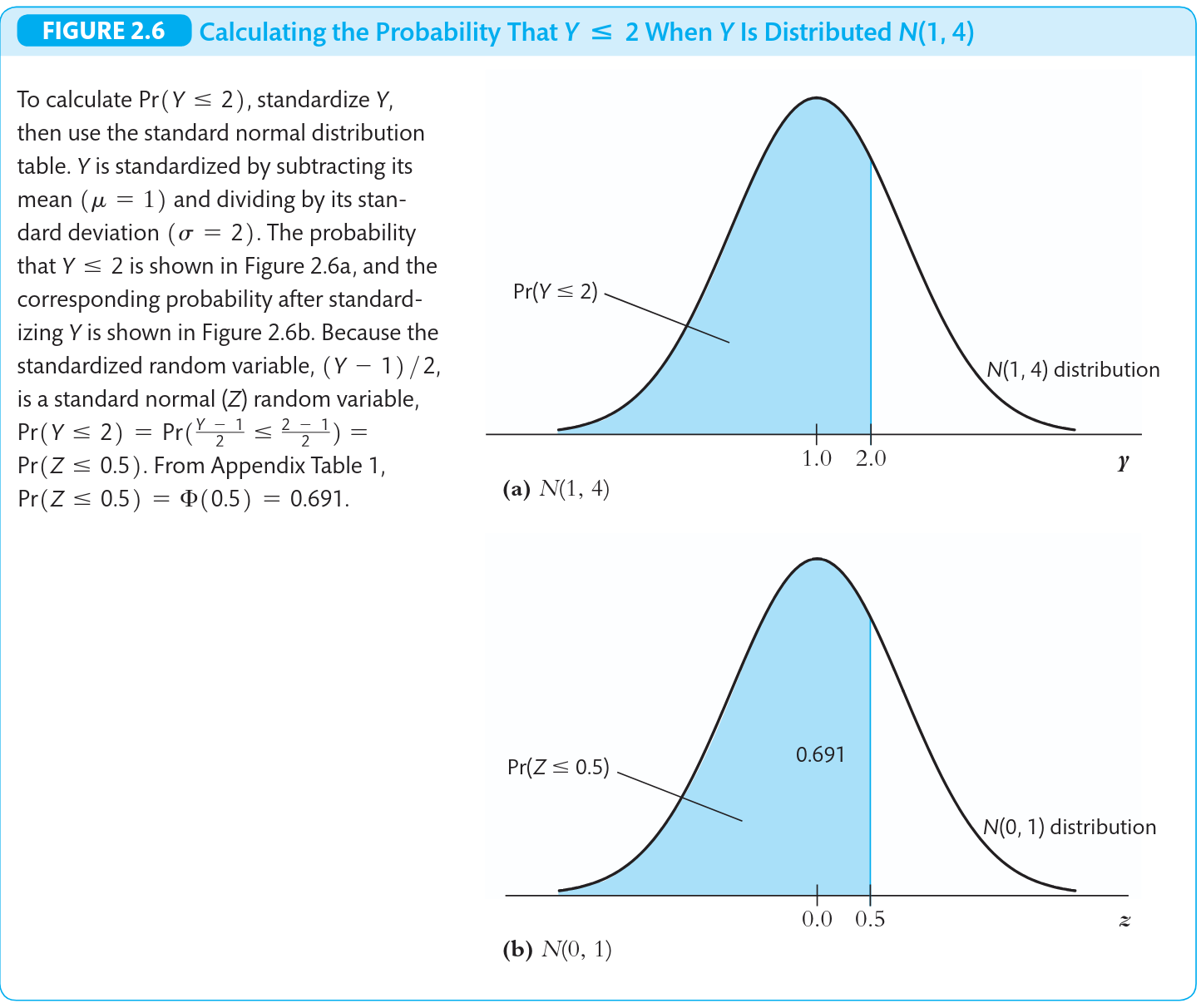
Veja o código
# Utilizar conjunto de pacotes tidyverse
library(tidyverse)
# Parâmetros para Simulação
set.seed(123) # Para reprodutibilidade dos resultados
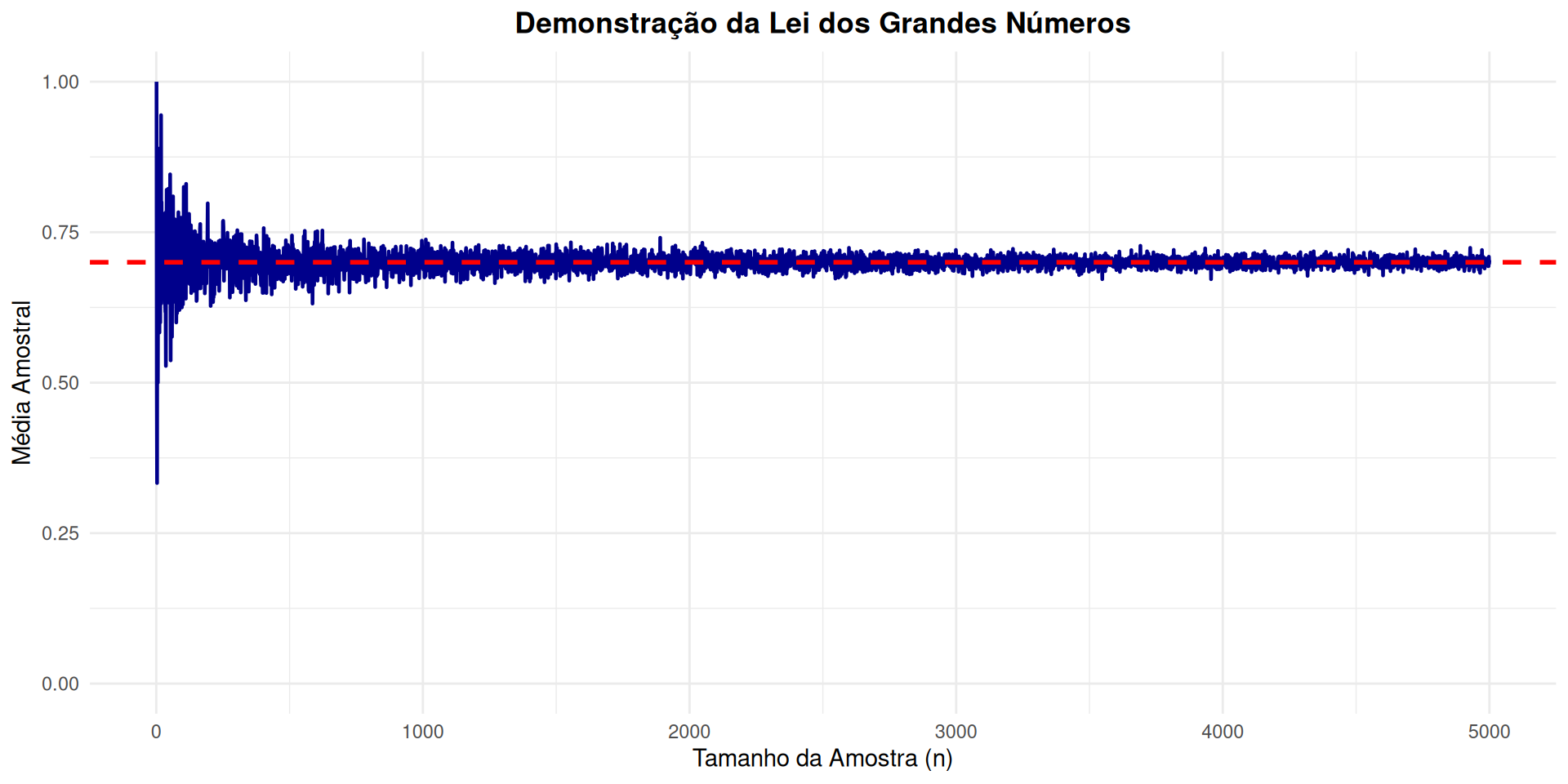
prob_sucesso <- 0.7 # A "verdadeira" média populacional (p) para uma distribuição Bernoulli
max_amostra <- 5000 # Tamanho máximo da amostra para simular
# Criar uma base de dados para receber os dados simulados
# Usar função 'map' (do pacote purrr) para aplicar funções a cada linha
sim_data <- tibble(n = 1:max_amostra) %>%
mutate(
# Gerar 'n' observações de uma Bernoulli para cada 'n'
amostras = map(n, ~rbinom(.x, size = 1, prob = prob_sucesso)),
# Calcular a média de cada amostra gerada
mean_sample = map_dbl(amostras, mean)
)
# --- Visualização dos Resultados com 'ggplot2' ---
ggplot(sim_data, aes(x = n, y = mean_sample)) +
# Linha que representa a evolução da média amostral
geom_line(aes(color = "Média Amostral"), linewidth = 0.8) +
# Linha horizontal para a verdadeira média populacional
geom_hline(aes(yintercept = prob_sucesso, color = "Média Populacional"),
linetype = "dashed", linewidth = 1) +
# Configurações de cores e legendas para as linhas
scale_color_manual(
name = NULL, # Remove o título da legenda
values = c("Média Amostral" = "darkblue", "Média Populacional" = "red"),
labels = c(
"Média Amostral" = "Média Amostral",
"Média Populacional" = paste("Média Populacional (p =", prob_sucesso, ")")
)
) +
# Títulos e rótulos dos eixos
labs(
title = "Demonstração da Lei dos Grandes Números",
x = "Tamanho da Amostra (n)",
y = "Média Amostral"
) +
# Limita o eixo Y para a escala de 0 a 1 (adequado para Bernoulli)
ylim(0, 1) +
# Tema visual minimalista para o gráfico
theme_minimal() +
# Ajustes finos no tema (título centralizado, posição da legenda)
theme(
plot.title = element_text(hjust = 0.5, face = "bold"),
legend.position = "topright"
)